



After speaking with over 20 clients about data quality in modern data pipelines, I am eager to share my insights on the pros and cons of internal (in-memory) processing versus external (API-based) DQ engine integration. Organizations are increasingly adopting diverse technologies to maintain data quality, making it difficult to choose the most effective strategy. In this blog post, I aim to present a collection of insights and best practices for data quality management in the pipeline, emphasizing the benefits of using APIs to integrate external data quality engines focused on data at rest.
Internal processing vs. external data quality solutions
In modern data pipelines, maintaining data quality is essential for deriving accurate insights and making informed decisions. There are two main approaches to consider for integrating data quality checks during the ETL process:
- Internal processing using existing functions
- External solutions that leverage an API-based DQ engine
Internal processing involves applying data quality checks and transformations, then persisting the data into the next stage of the pipeline. While this approach enables real-time data quality checks, it can be resource-intensive, especially for large datasets. Moreover, ETL failures may still occur during the loading process (L), potentially causing data inconsistencies between the staging and landing zones, despite validating post extract (E).
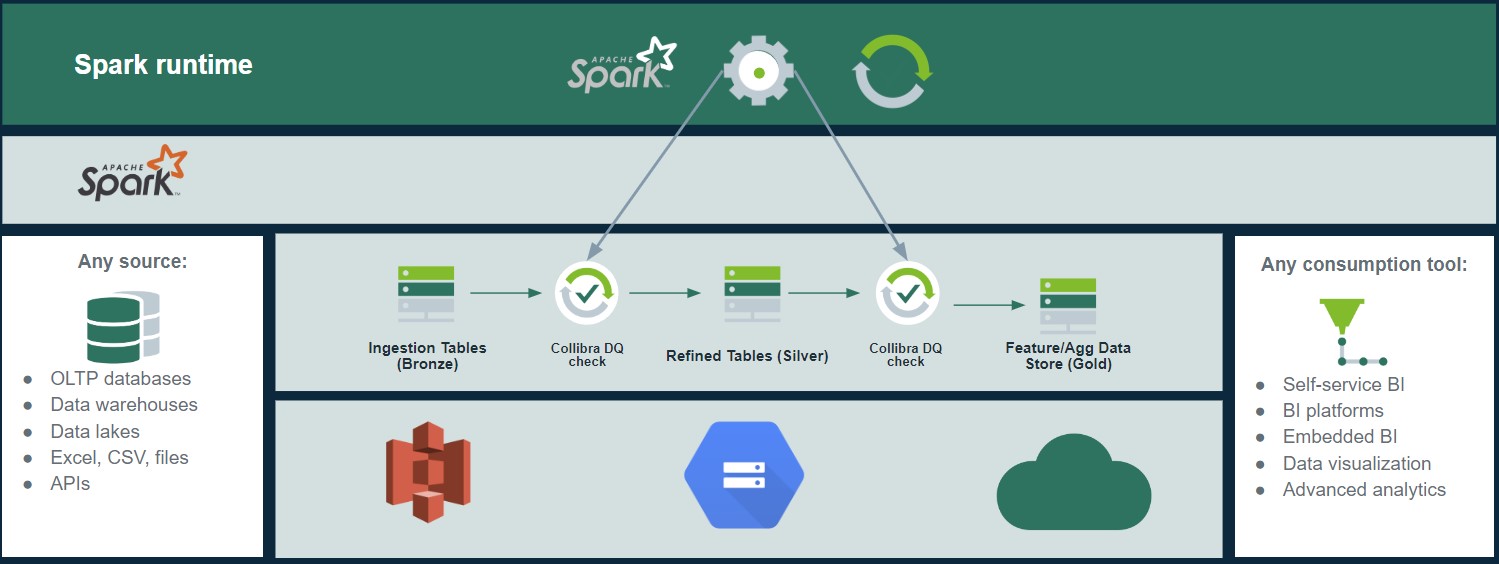
Alternatively, external data quality solutions allow organizations to harness the power of an API-based DQ engine, providing a more scalable and efficient option. REST APIs facilitate the integration of external data quality engines via a standardized interface, frequently using a UI. This method mitigates the risk of ETL failures and guarantees consistency between staging and landing zones. Data continues to be checked within the pipeline without overburdening a single function.
When employing both internal and external DQ approaches, you can direct your data quality checks to be applied to various types of data:
- Data at rest, such as when stored in a database or data lake
- Data in movement, like streaming data or during the ETL process
Notably, a pipeline can have instances of resting data while in movement, as in the case of Kafka topics and queues or more structured zones.
By drawing inspiration from software development and treating data as code, data pipelines can be designed to apply similar best practices found in CI/CD (Continuous Integration/Continuous Deployment) pipelines. Jenkins doesn’t just pull a snippet from JIRA into production.
Best practices for designing data pipelines with data quality checks
Integrating data quality checks at various stages of the pipeline ensures data is validated and cleansed before progressing to the next stage. It mirrors the way code is tested and refined through multiple environments before deployment.
There are several best practices to consider when designing data pipelines that incorporate data quality checks:
- Modular design: Create a modular pipeline design that separates data quality checks, transformations, and storage, making it easier to maintain, scale, and update. This approach allows for flexibility in choosing between internal and external data quality checks or even a combination of both.
- Continuous monitoring and validation: Implement continuous monitoring and validation of data quality throughout the pipeline, ensuring that any issues are detected and resolved promptly. This practice helps maintain overall data quality and enables better decision-making based on accurate and reliable data.
- Version control and data lineage: Treat data as code and apply version control practices to track changes in data quality checks, transformations, and schema. Maintain data lineage to ensure traceability and accountability, making it easier to debug and resolve issues when they arise.
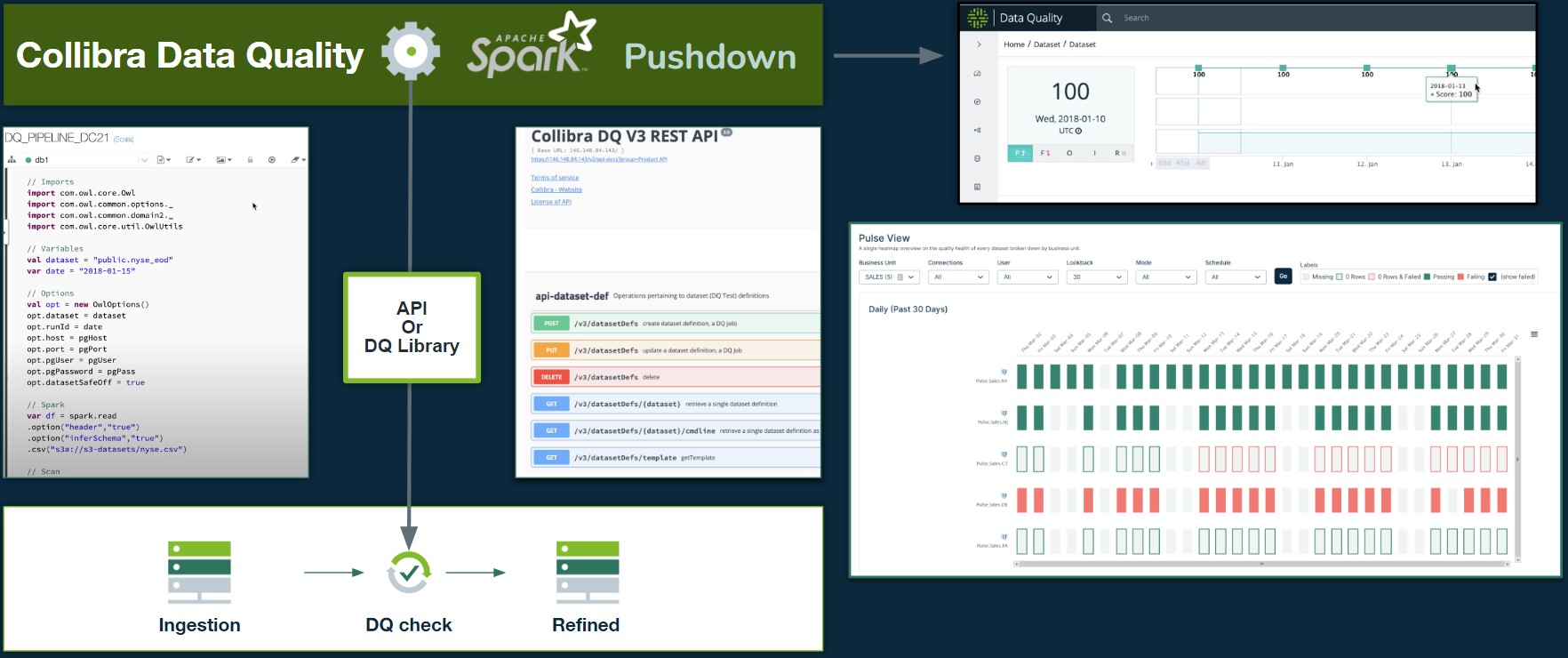
In terms of scalability, external solutions provide a more modular, maintainable, and scalable approach to managing data quality. APIs offer a standardized interface for integrating data quality checks into existing data pipelines, making it easier to incorporate new validation rules or update existing ones. This flexibility reduces the need for extensive rework and redesign, allowing development teams to allocate resources more effectively and focus on higher-priority tasks.
Real life examples
One of our clients, a prominent financial services company, provides a compelling example of the benefits of external data quality solutions that target at-rest data. Initially, the client employed a Kafka streaming architecture to manage their massive data processing requirements. But they struggled to maintain data quality within their data lake.
Integrating data quality checks within the Kafka streaming architecture would have resulted in a 35% surge in infrastructure and maintenance expenses and a 20% increase in development costs compared to an API-based approach.
By embracing an API-based data quality solution, the client streamlined their operations and eased the burden on their resources, leading to a 25% reduction in infrastructure costs and a 15% decrease in development costs. Additionally, enhanced data quality enabled their analytics team to derive more accurate insights. In turn, it improved decision-making and positively affected the company’s bottom line.

A critical insight from this financial services company’s experience was that scanning Kafka topics and queues for data quality checks proved inefficient. They discovered that conducting data quality scans on larger staging zones, where data is at rest, offered a more efficient and effective method.
By concentrating on scanning at-rest data in staging zones rather than in-memory data or overloading Kafka topics and queues, the client established a more resource-efficient solution for ensuring data quality. This approach allowed them to capitalize on the benefits of API-based data quality checks while minimizing the impact on their real-time data processing infrastructure.
Conclusion
Ultimately, while both internal and external DQ solutions have their merits, API-based approaches offer several advantages, particularly when it comes to scalability, efficiency, and cost-effectiveness. I encourage organizations to consider their specific use cases and requirements when choosing a DQ approach. By doing so, businesses can harness the full potential of their data, drive better decision-making and achieve a competitive edge. Some scenarios might still benefit from internal processing, especially when real-time data quality checks are crucial.
Collibra Data Quality & Observability can support both in-memory and API-based DQ processing, providing flexibility and versatility for our clients. Our DQ library enables seamless integration with various programming languages, such as Scala and Py4J, catering to different use cases and technology stacks. Check out how our solution could meet either of your use cases!


