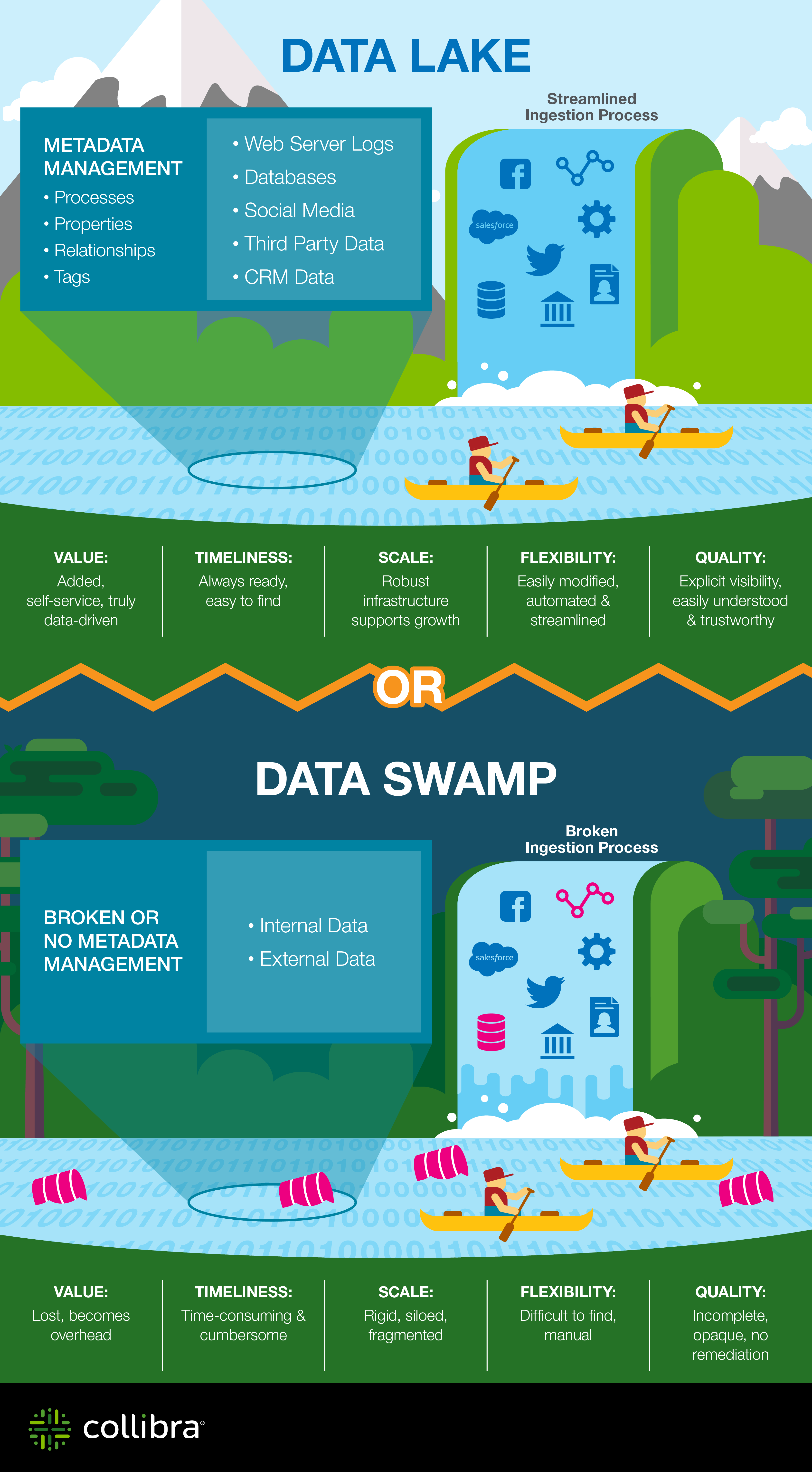
Anyone who has been looking at big data for any length of time is likely already overexposed to the “data lake vs. data swamp” analogy. The analogy assumes that a “lake” is somehow neater and more orderly than a “swamp.” But the only reason a lake appears to be more orderly is because the complexity of all the physical formations and living creatures is below the surface of the water, whereas in a swamp some of these complexities are exposed for all to see.
It turns out that visibility of details is one of the major problems with data lake management. The volumes of data, and the number of repetitive versions of data, make it impossible to accurately identify the correct data from its structural characteristics. And nomenclature that differs between business departments means that user-added information can be misinterpreted without common reference data and semantic agreements.
But because the economics of the data lake are so compelling, organizations have often begun by putting data into the lake without clear information about what currently exists. This creates two outcomes:
- The data in the lake is really only usable by those who already know what it is and what it means. If a different set of users have access to the same data, they will create a replica and label it in their own terms. The outcome is that the lake becomes a siloed environment, where the commonality of infrastructure does not lead to any sharing of information. And in fact, it actually can proliferate copies because of the low cost of additional storage.
- Without enough information, it is hard to distinguish the data in the lake. It becomes not so much a swamp but rather a pit of mud. Everything looks the same and you cannot tell the good bits from the bad.
Cleaning up the lake is not about making it look more orderly and placid, but rather making it so you can see all the features of what is in it – more like the swamp. Of course, we cannot go back to the model where everything must be completely described before being made available, as was the case with many data warehouses (and we all know how that story ends). Instead, a process that collects metadata across its initial registration and continuously gathers more information as people use the data is the best way ensure flexibility and to capture opportunity for reuse and sharing.
This approach also ensures that the people who know about the data (because they produce and use it) are the ones that describe and record information about it. And people will do this willingly because they see the value, as having this information also makes it easier to find and use the data in the lake. So it is a fair exchange: ease of access for what you know about the data and how you will use it. At present, this is the only viable approach that will scale naturally.
Many technologies promise to solve the problems of the data swamp. And while they do address aspects of the problem, the primary challenge is making sure that data set can be seen for what it is, rather than be hidden below a seemingly placid surface. To address this challenge, organizations must make their data visible in the lake and connect the process of finding data (through the data catalog) to the process of collecting information about the data. Without that connection, the data lake may appear calm, but it will just be a featureless expanse instead of a rich, diverse landscape.