



The FAIR Data Principles for scientific data management and stewardship were first introduced and published in scientific journals in 2016. At its core, FAIR aims to break down data silos by providing guidelines to make data:
- Findable – metadata and data should be searchable and should be easily located.
- Accessible – metadata and data should be accessible to users.
- Interoperable – data should be formatted in a way that it can be stored, accessed and processed by multiple applications. It can be integrated with other data. Additionally, metadata should include qualified references to other metadata.
- Reusable – metadata should include rich business and technical context. It should be well-described so that it can be replicated.
By adopting FAIR Data Principles, life sciences firms (pharmaceuticals, biotech, medical device manufacturers) can accelerate data sharing, improve data literacy (understanding of data) and increase overall transparency and auditability when working with data. Ultimately, leading to greater innovation and efficiencies in life sciences – across R&D and commercial operations.
According to IDC, healthcare and life sciences combined represent over 30% of the world’s data with a CAGR of nearly 36%. It is predicted that researchers, on average, can generate approximately 10s of TB of data each day.
This data sprawl is further exasperated by the fact that life sciences firms operate in a highly complex data landscape. For instance, it is not unusual to find petabytes of data spread across hundreds if not thousands of disparate data sources at a global pharmaceutical firm.
Add to this, the hurdle of managing data in a highly regulated industry where virtually every regulation governing life sciences calls for a rigorous data management and data integrity strategy. The stipulations surrounding data integrity are extensive. For instance, they range from how data should be handled, accessed and processed to how data should be stored, retained and who should have access to what types of data. All regulations require comprehensive audit trails for compliance reporting purposes. It is no surprise that adopting FAIR Data Principles is a top priority for life sciences firms globally.
How Collibra Data Intelligence Cloud can help
At Collibra, we work with leading life sciences firms globally – including pharmaceuticals, biotech and medical device manufacturers – to help them innovate with data. Our customers are using Collibra Data Intelligence Cloud to make their data FAIR.
FAIR data is a foundational pillar for building a data marketplace to allow researchers and data scientists to easily discover, explore and collaborate with data. Moreover, data that’s governed, trustworthy, traceable and of high quality is critical for accelerating self-service analytics and artificial intelligence (AI) initiatives for many of our customers.
Collibra Data Intelligence Cloud is an intelligent data platform that leverages the power of machine learning and provides a holistic and integrated approach to cataloging, governing, protecting, managing and collaborating with data at scale across on-premises, hybrid and multi-cloud environments.
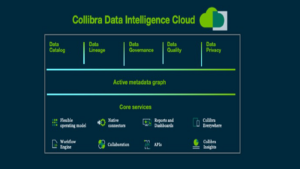
Life sciences organizations rely on Collibra Data Intelligence Cloud to:
- Rapidly catalog all their data regardless of where it resides to create a single, trusted repository of metadata (data about data). The catalog offers advanced capabilities that are purpose-built to empower users to easily find and understand the data they need with rich business and technical context at a granular level.
- Enact a comprehensive data governance strategy and develop a consistent data taxonomy, data usage registry, physical and/or logical data dictionary and glossary of terms. With Collibra Data Governance, organizations can speed up the automation of complex policies, rules and guidelines that enable them to ensure adherence to Identification of Medicinal Products (IDMP), Good x Practice (GxP), Drug Supply Chain Security Act (DSCSA), Federal Food, Drug and Cosmetic Act (FD&C), The Physician Payments Sunshine Act, General Data Protection Regulation (GDPR), and more. Pre-built templates, out-of-the-box data domains and intuitive workflows provide a framework for cross-functional teams to establish a common understanding of data to ensure consistency.
- Address data quality and privacy issues at scale to ensure data integrity. For instance, Collibra predictive data quality and observability leverages machine learning (ML)-enabled capabilities to proactively detect anomalies in data such as missing records, values as well as broken relationships across tables or systems resulting in rapid resolution. Moreover, advanced capabilities in data privacy and protection helps ensure sensitive data is easily identified and fully protected with role-based access control.
- Obtain end-to-end visibility with automated data lineage and an active metadata graph enabling users to easily visualize the flow of data from source to target as well as understand all the data dependencies at a granular level.
Next Steps:
To learn more, I would like to invite you to watch the following webinars:
- The Journey to Data Intelligence in Life Sciences & Pharma – featuring Genentech/Roche Group
- Data Intelligence in a Modern Healthcare Organization – featuring Mayo Clinic
- Building the Case for Data Governance – featuring AstraZeneca


