


In a world getting flooded with all kinds of data, the obvious concern is – how to turn data into an asset. Data engineers, data stewards, DataOps engineers, rule writers, and other overlapping roles strive to make data ready for work. But is this data of high quality? Is it reliable? What about its integrity? Can it be trusted to power analytics and operations?
The data quality landscape is swamped with home-grown solutions or siloed products focused on detecting data quality issues. They work with manual rule writing and automated data quality checks. But they get overwhelmed when large volumes of data start arriving constantly from everywhere. They also cannot cope with diverse sources or data formats, nor can they scale easily when the business grows. Moving to the cloud has its own demands, and managing data quality in a hybrid environment is challenging.
Break free from this inefficient status quo – with Collibra Data Quality & Observability!
Power your business outcomes with predictive data quality, end-to-end data observability, guaranteed data reliability, and assured data integrity.
Auto-generated rules
The AI-driven Collibra Data Quality & Observability can scan any data source and autogenerate adaptive rules. The intelligent rule discovery takes just minutes against the tedious, error-prone, manual rule writing of months. Moreover, the rules quickly adapt to the changes in data formats or shapes, which today are increasingly common. What more can rule writers ask for?
Unified scorecards
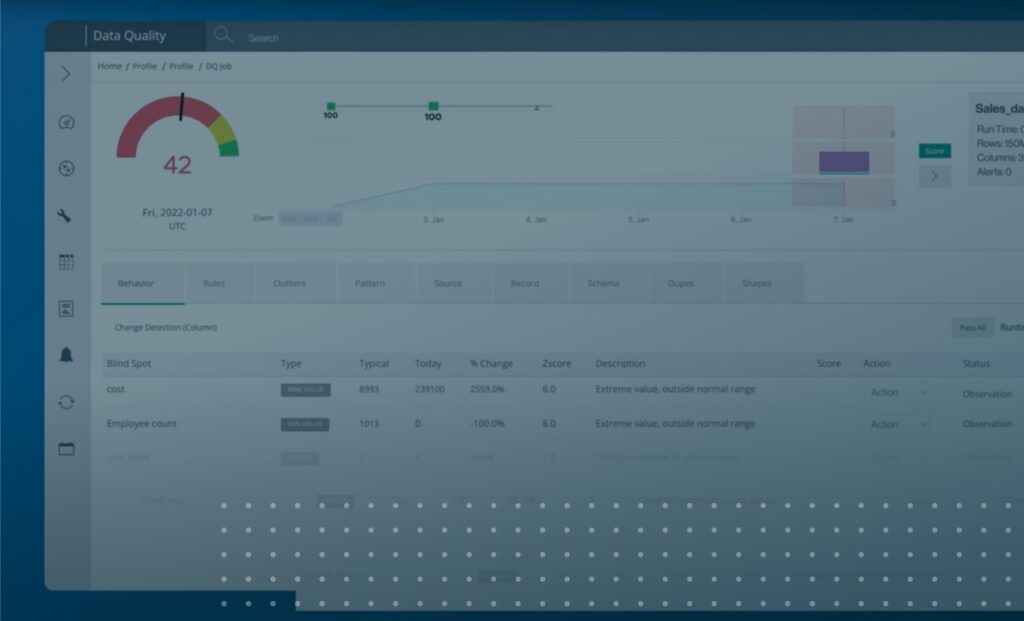
Unified scorecards present a continuously updated status of quality issues across diverse databases, data warehouses, and data lakes, helping manage them effectively.
End-to-end data observability
End-to-end data observability can discover anomalies proactively in real time and prevents them from reaching downstream applications. Data engineers can leverage data observability to detect outliers, patterns, schema changes, or duplicates. Data observability empowers DataOps engineers and data engineers to start from the point of failure and follow the path of data upstream. Detecting the root cause of data issues helps fix it at the source and ensures that it does not appear again.
Guaranteed data reliability
Continuously monitoring data pipelines helps detect issues in real-time to guarantee reliable, accurate, secure, and compliant data across the enterprise. Personal alerts enable assessing the priority for quick action to resolve issues.
Assured data integrity
Collibra Data Quality & Observability assures high integrity of data and relationships as it moves across various enterprise applications. Adding context and relationships enriches data to deliver deeper insights, powering better business outcomes.
Setting up in a single sprint
The no-code data quality and observability with native connectors and out-of-the-box algorithms enable data engineers to start delivering results in a single sprint.
The solution easily scales the data quality checks to manage the large data volumes, providing trusted data for every user across every source. The self-service solution enables all stakeholders to contribute actively towards consistent, enterprise-wide data quality.
With Collibra Data Quality & Observability, data engineers can streamline delivering error-free data to downstream operations. Together with data stewards, DataOps and data engineers can:
- Build healthier data pipelines with continuous data monitoring and alerting.
- Supplement data quality rules with ML-generated, adaptive, explainable DQ rules.
- Identify data quality issues fast (at the source) and prevent them from propagating downstream.
Be the first to know about silent data bugs, broken dashboards, schema changes, distribution drift and stalled jobs. Achieve healthier data, trusted insights, and better business outcomes with Collibra Data Quality & Observability!


