



Well, is it? For many, the answer is probably not. And it isn’t because you don’t have great governance or have your data cataloged to the nines, it’s because in order for data to be ready for AI, there are a specific set of criteria that need to be checked off. We’ll get to that check list in a bit more detail later in this blog, but first a little primer on how data and AI work together.
Data + AI = a host of different answers
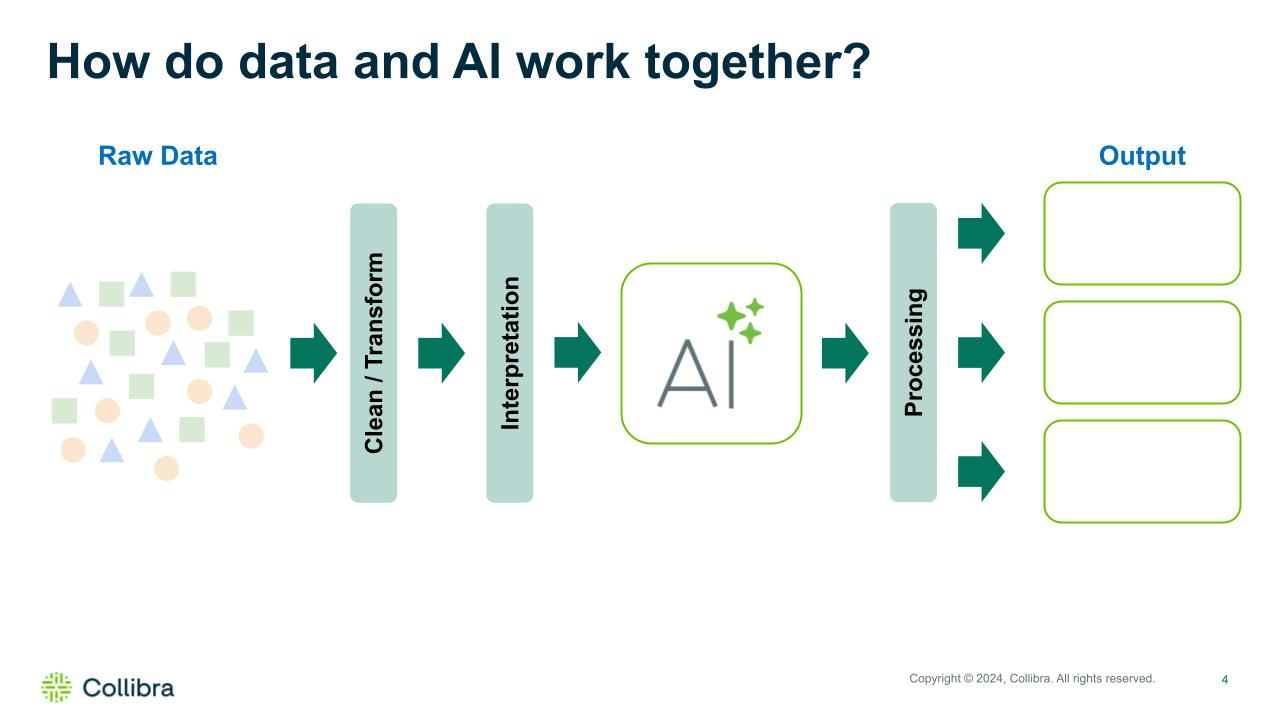
If you’re new to AI, an AI model is fed by data. The AI model (or sometimes algorithm) take the data that is fed into it and analyzes patterns to then give responses/answers/insights that can help you make better decisions, or in the case the of GenAI (think ChatGPT) write you a story or even create a piece of art based on your request. Data goes in, responses come out. Pretty simple. However, the quality of the data being fed to AI makes all the difference in the world.
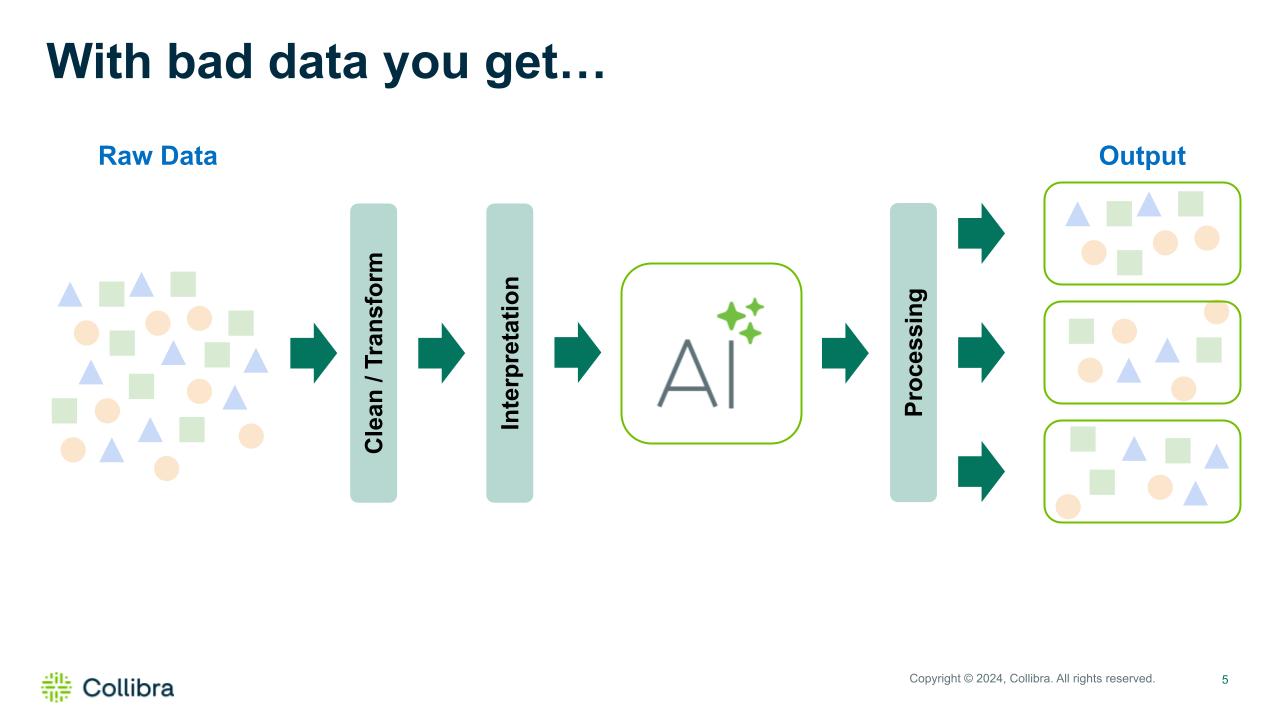
In the example below, we’re starting with poor quality data. It’s full of bias, is incomplete, and is years old. When we move from raw data through the AI model, we’re presented with nothing useful. Think about the real world consequences – inaccurate results, bad decisions being made, privacy violations, legal and brand implications, the list goes on. For example, what could happen if a credit scoring model contained bias or a cancer diagnosis model was built using poor demographic-specific data?
AI with bad data – garbage in, garbage out
Now I know that none of you reading this would start your AI project with this state of data, so let’s take a look at our output when we start with good data. As you can see, there’s more accuracy, more order to the outputs. However, it still has problems. Even if our data is good, we have risks that we shouldn’t be willing to accept. Outputs are scattered (which could lead to bias in the subpopulation following our example of the credit score app above), responses can’t be trusted and we’re still left to do extra validation work, adding time and expense to our project.
AI with good data – better, but not quite there
Finally, we’ll use AI-ready data. As you can see, with AI-ready data, the output is more structured, organized. With AI-ready data, our outputs can be trusted and we can help mitigate risks. We’ve all seen the headlines of what happens to organizations that deploy bad AI – if they had started with AI-ready data, they may not have been a headline at all.

AI with AI-ready data – outputs that you can trust
I can hear some of you now saying “But we’re already a data driven organization”. I hope at this point we all are. But being data driven doesn’t mean the right checks and balances are in place to ensure data is ready for AI. For your data to be AI-ready, it needs to be…
What is “AI ready data”?
Many of you are already on the path to having AI-ready data which is fantastic. Below is a simple checklist of how you can ensure your data is up to par:
- Governed – Data has defined policies, processes, and roles for data handling
- Secure – Data has well defined policies for who can see, use, and access data both up and downstream
- High-quality – Data pipeline reliability is continuously monitored to help quickly identify and remediate anomalies
- Accessible – Data is easily discoverable for everyone in the organization with a searchable, curated subset of assets
- Bias free – Data is high-quality, diverse, complete, and takes into account edge cases
If you can say yes to these five items, congratulations, you’re ahead of the game. This is critically important with new AI laws and regulations coming on line. For example, the European Union AI Act (EU AI Act) which went into effect in August 2024, has specific requirements for data especially in “high risk” use cases. Article 10 states that these systems “must be developed using high-quality data sets… should be managed properly… and should be relevant, representative, error-free, and complete as much as possible.”
Learn more about how Collibra can help with the EU AI Act.
In the United States, White House memorandum M-24-10 (Advancing Governance, Innovation, and Risk Management for Agency Use of Artificial Intelligence) also has specific data clauses, stating, “Agencies should develop adequate infrastructure and capacity to sufficiently share, curate, and govern agency data for use in training, testing, and operating AI,” and further states “Any data used to help develop, test, or maintain AI applications, regardless of source, should be assessed for quality, representativeness, and bias.”
Learn more about how Collibra can help with M-24-10.
Whether bound by laws or not, ensuring the AI you use or develop starts with AI-ready data is something every organization should strive for to ensure that users, both internal and external, can trust in what is being delivered to them through AI and how it is being used.
How can you ensure your data is AI-ready?
Ensuring your data is AI-ready isn’t a huge mountain to climb if you know where to start. Here are some pointers to get you moving:
- Treat data as a product. Data products have an owner which adds a layer of accountability. A data product includes:
- Data
- Context
- Access
- Service levels and contract information
- Make sure data is findable. Implementing a curated data marketplace is a great place to start.
- Ensure data is accessible. Do the right people have access to it? Make sure that data, regardless of where it lives, is able to be used (and make sure to have the right security controls in place!)
- Data needs to be usable across a variety of platforms. It’s likely that your data science teams have multiple tools they are using to build models. Make sure each of those tools or platforms are able to use your data.
Where to begin?
Recently, Collibra Product leaders Wouter Mertens and Ashley Blake held a webinar on this very topic. You can watch the on-demand version here. They had a ton of great insights and suggestions to share and hopefully, you’ll be able to use those as you continue your AI journey.
AI is just that, a journey – no matter how deep you are with your data and AI progress, you need to get started cataloging your AI use cases and ensuring your data is AI-ready. Many organizations feel like it’s too early to think about governing their AI, but it’s just the opposite – the earlier, the better.


