



In today’s data-driven world, businesses rely heavily on the accuracy and reliability of their data to make informed decisions. Whether it’s monitoring revenue, managing risks, or optimizing operations, the quality of the underlying data is crucial. Data quality (DQ) issues—like typos, outliers, or invalid entries—can lead to misinformed decisions and flawed insights. Organizations often face challenges when trying to ensure their data remains accurate and reliable over time.
Collibra Data Quality & Observability provides a comprehensive solution to address these challenges by automatically detecting data quality issues using a combination of machine learning (ML) and rule-based approaches. But how do you know which DQ issue you’re dealing with and how to resolve it?
As datasets grow in complexity, with varying formats, sources, and structures, manually defining and maintaining data quality rules becomes overwhelming. Some of the most common data quality challenges include:
- Data Discovery and Classification: Identifying the semantic classification of data such as email, credit card number, tax identification number and sensitivity of the data
- Data Shape Issues: Inconsistent formats across columns, such as phone numbers or ZIP codes, create discrepancies in string fields
- Row Count Drops: Sudden decreases in dataset volume, indicating missing or incomplete data
- Missing or Invalid Data: Incomplete data observations or values outside valid ranges (e.g., a FICO score that doesn’t fall between 300 and 850)
- Schema Drift: Structural changes, such as added or dropped columns, impacting the overall integrity of the dataset
- Source to Target Validation: Ensure data is not lost or altered in a way that deteriorates quality as it is moved from source to target
- Custom Business DQ Rules: The need to define specialized rules using SQL functions for unique business requirements
Organizations often struggle to address these issues manually, especially with thousands of columns, rows, and multiple data domains. The excessive manual effort results in inefficiency, delays, and incomplete data quality visibility.
Collibra’s Data Quality & Observability platform simplifies these challenges by providing a robust, automated solution for defining and managing data quality rules:
- Data Discovery and Rule Enforcement: Automatically detect data classes and assign sensitive labels such as personally identifiable information (PII). Learn more in this video
- Auto-generated & Adaptive Rules: Using ML, Collibra auto-generates SQL-based, explainable, and adaptive data quality rules that evolve with the dataset, reducing the need for manually written rules. Learn more in this video
- Outliers and Anomaly Detection: Automatically detect outliers by grouping subsets of data and benchmarking against past trends, avoiding the manual maintenance of conditional statements. Learn more in this video
- Schema Drift and Data Shift Detection: Automatically flag changes in data structure, such as new columns or altered field types, and shift in normal data distributions to ensure data integrity is maintained. Learn more in this video
- Source to Target Validation: Automatically validate data that is moved between applications, databases, warehouses and lakes. Such as cloud modernization of warehouses and lakes. Learn more in this video
- Business DQ Rules: Leverage pre-built SQL functions and translate business rules into technical rules using GenAI powered natural language to SQL generation
Here’s a view of how easy we make custom rule creation.
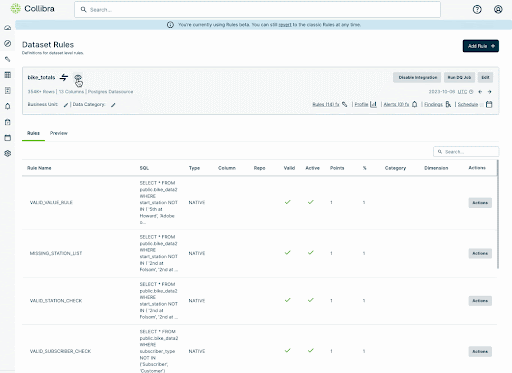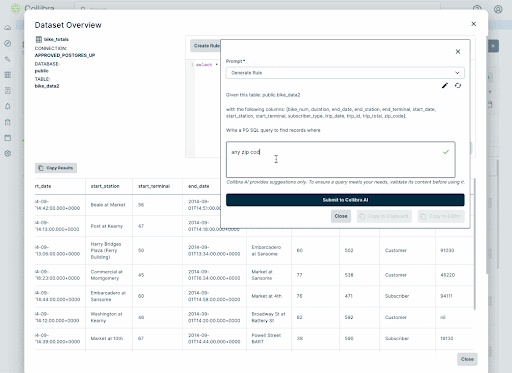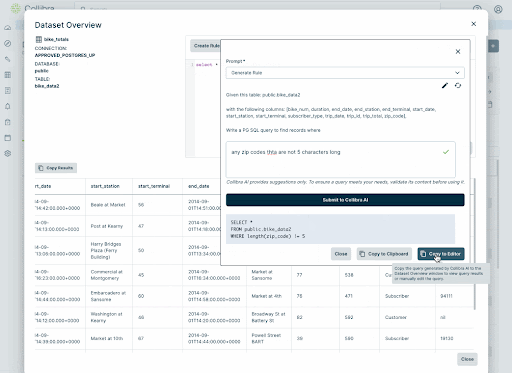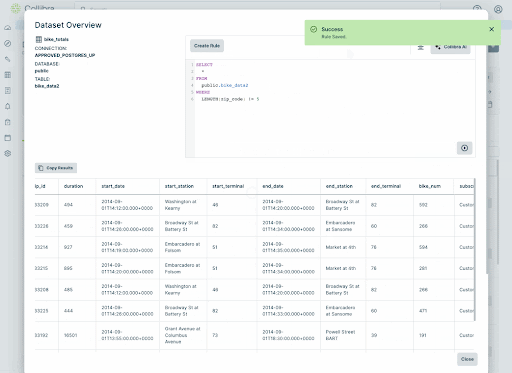
Collibra’s comprehensive rule management capabilities enable organizations to simplify and accelerate their data quality management. With our machine learning-driven rule generation, adaptive thresholds, powerful anomaly detection, and GenAI rule building capabilities you can ensure reliable and trusted data faster and with less work.
For more tips on ensuring reliable data check out our data observability workbook.


