



Today’s insights-driven organizations harness vast amounts of data to fuel AI models, drive analytics, and inform strategic decisions. However, the sheer volume and complexity of data in cloud platforms can pose significant challenges in ensuring trusted and reliable data. The fourth quarter release of Collibra Data Quality and Observability provides new and enhanced functionality to help customers simplify and scale their data quality efforts.
Pushdown processing for Microsoft SQL Server and SAP HANA and Datasphere
Increase scalability and reduce cost of monitoring and validating data quality in SAP Hana and Datasphere with pushdown processing. Pushdown processing refers to the technique of executing data processing tasks directly within the data storage system (e.g., a cloud database) rather than transferring data to an external processing engine. This approach leverages the native capabilities of modern cloud environments like Microsoft Azure and SAP HANA and Datasphere to minimize data movement, reduce latency and optimize performance.
Pushdown processing enhances scalability by allowing the cloud platform to manage and process large volumes of data efficiently. This capability is crucial for organizations dealing with extensive datasets comprising thousands of tables and hundreds of columns. Pushdown processing also enhances data security by ensuring that data remains within the secure boundaries of the Microsoft and SAP cloud environment. This minimizes the risk of data breaches and ensures compliance with data protection regulations.
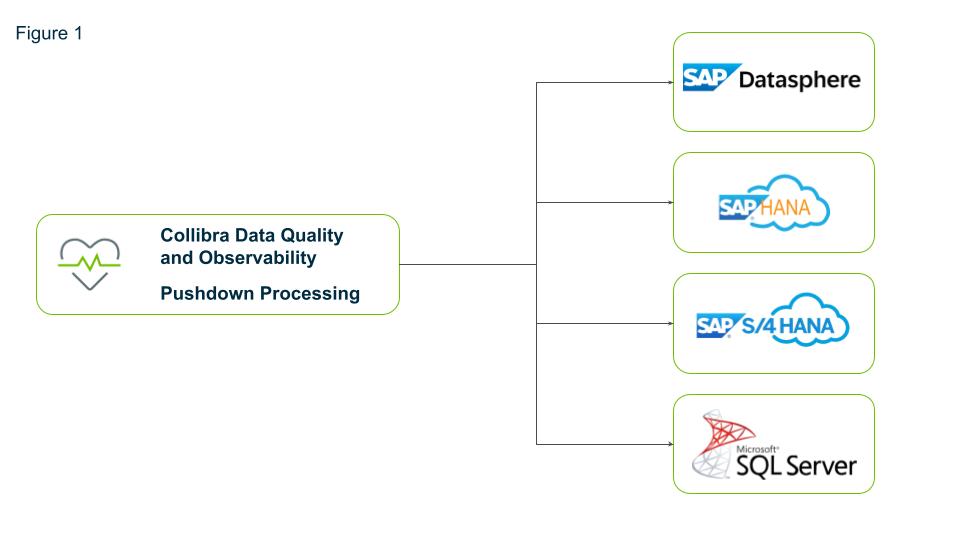
Figure 1: Pushdown processing with Collibra Data Quality and Observability
See the documentation to learn more about pushdown processing and the checks you can perform to ensure reliable data.
Enhanced mapping of data quality rules and metrics to data catalog assets
Gain greater visibility of data quality with automatic mapping of quality rules and metrics to schemas, tables, and columns in the data catalog. Attaching data quality scores to data assets allows users to quickly gauge the reliability of the data they intend to use. This immediate visibility ensures decisions are made using the best available data. And by reducing the time spent manually assessing data quality people can spend more time on using the data to improve business outcomes.
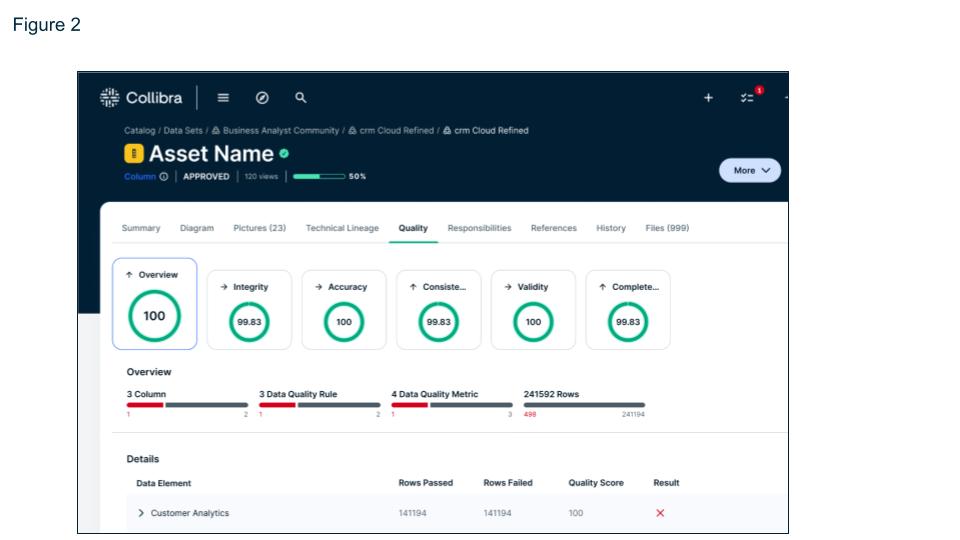
Figure 2: Data asset quality is available directly from the catalog
Visibility of data quality from source to catalog instills trust in the data and confidence in decisions by providing transparent and objective assessments of data reliability. This trust is crucial for the adoption and success of AI initiatives and analytical projects.High-quality data ensures that AI models are trained on accurate and representative data, improving their performance and reliability. Clear visibility into data quality helps stakeholders trust the data being used, leading to greater acceptance of AI-driven insights.
We’ve got all of the documentation you need here, to get data quality integrated into your data catalog.
Enhanced mapping of data quality rules and metrics to data governance policies
Linking data quality scores with data governance policies ensures that data management practices align with internal organizational standards and external regulatory requirements.Governance without enforcement is just documentation and this integration ensures accountability and compliance with business controls.Data stewards and owners can be held accountable for maintaining data quality, promoting continuous improvement. And organizations can provide auditable proof of data quality controls and that only data meeting regulatory standards is used in critical processes.
The enforcement of governance policies through data quality controls streamlines compliance processes, reducing the burden of manual oversight and minimizing the risk of non-compliance.Data that falls below quality thresholds can be automatically flagged for review or excluded from certain processes.Reports and audit trails provide proof of ongoing monitoring, anomaly detection, cause and impact analysis, issue management and compliance with standards and regulations.
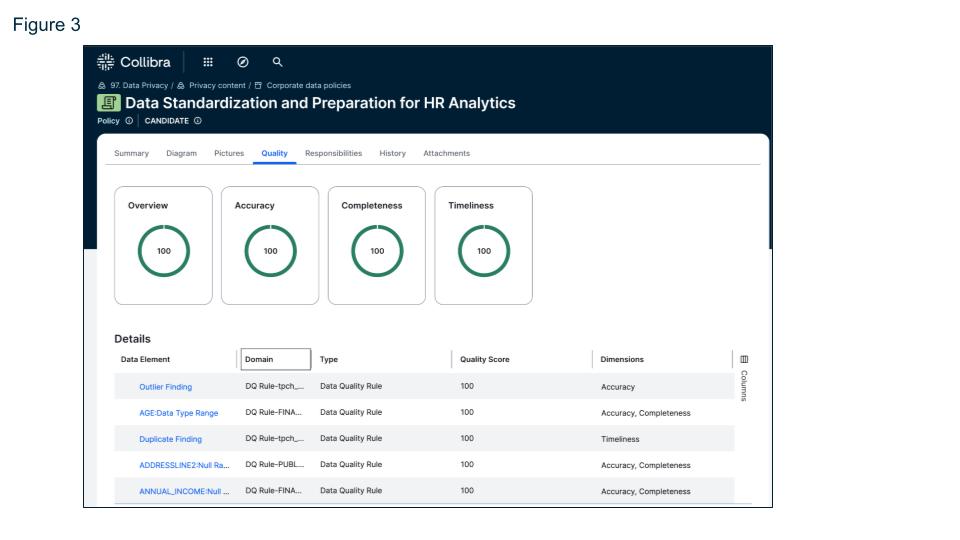
Figure 3: Data quality rules and metrics linked to governance policies
Compliance visibility is easier than ever, and our documentation can show you how.
Improve the scalability, productivity, trust and compliance of your data quality efforts
Pushdown processing for Microsoft SQL Server, SAP HANA, and Datasphere enhances scalability and reduces costs by executing data processing tasks directly within the data storage system, leveraging native cloud capabilities to minimize data movement and optimize performance. This technique, combined with enhanced mapping of data quality rules and metrics to data catalog assets, provides greater visibility and reliability of data. By linking data quality scores with governance policies, organizations ensure compliance with internal and external standards, promoting accountability and continuous improvement. This integration allows for auditable proof of data quality controls, ensuring only data meeting regulatory standards is used in critical processes.
To learn more about Collibra Data Quality and Observability check out the product tour.


